博主的一些废话
作为这个博客第一篇正经的文章,没点干货怕是镇不住场子。去年年底来了一波矿难,我也就趁显卡价格崩盘之前,卖光了我全部的显卡,然后以500多块的价格搞了一个二手的RX 580 4GB。不得不说这个价格真的是香。再加上近两年来,基于面向风口编程的思想,自学了一些深度学习的知识,所以不得不好奇目前AMD GPU在深度学习框架加速上到底搞得怎么样了。不搜不知道,一搜吓一跳,目前关于AMD GPU for deep learning的讨论非常匮乏,尤其是针对PyTorch的讨论,英文的内容(包括官方文档)都有些过时,中文的讨论更是完全没有。本文很荣幸的能成为了也许是全网首发中文版PyTorch on AMD GPU的攻略。本篇博文主要介绍如何在容器(Docker)环境中部署PyTorch on ROCm,更希望在原生Ubuntu环境中部署的朋友可以参考我的【这篇博文】。
趁着今天AMD在台北的风光表现,想先聊聊AMD是如何在两年时间内180度扭转我对它的看法的。虽然早在2016年就听到过AMD ROCm的风声,但是说实话那个阶段的我还是有点看不起AMD的。彼时的AMD,CPU方面,zen架构吹了两年,但是还看不见影子;GPU方面,Raja大神年年rebrand上瘾,迟迟拿不出能和Maxwell正面竞争的产品,更何况下半年大杀特杀的Pascal。吹了半天的Polaris也就靠着制程优势才勉强达到GM204的水平。
直到后来的2017年,Dr. Su祭出大杀器Ryzen系列CPU,我对AMD的看法才算有点改观。后面的故事大家应该比较熟悉了,2018年的二代Ryzen补全了一代一些兼容性和内存控制器性能方面的问题,得益于多线程性能和价格优势,得到了市场良好的反应。而老对手Intel这段时间里可谓是多灾多难,超线程相关的安全性问题出了一个又一个,每次补丁都降一点性能。今天,Dr. Su又风光满满的宣布了zen2架构的三代Ryzen CPU,首发7nm桌面处理器,IPC+15%, 2$\times$浮点性能和2$\times$缓存容量;同时隔壁蓝队14nm工艺+了又+,谁来和我说一下最新的14nm工艺后面有几个加号了,桌面级的10nm处理器要到2020年末才能上线。至此AMD的CPU产品线算是对Intel完成了全面的超越,包括游戏、工作站、笔记本和服务器四大平台。
这段时间里AMD的GPU尽管产品线依然走的很艰难,但是有一个重要的变化不可忽视:大神Raja终于转投Intel,不再祸害AMD,把Radeon部门搞得全是咖喱味了,这段话会变得非常政治不正确,please bear with me。我对Raja大神的负面看法偏见也是有依据的:Raja在AMD的这段时间内,做出最大的贡献就是把显卡部门变得更加独立了,产品力方面则是一年比一年不给力,和老对手NVIDIA的差距从六四开变成了九一开,不得不让人联想到“硅谷里的印度人只会吹牛皮和搞办公室政治”这个传言。当然啦,Raja大神去了Intel之后是风采依旧,下面给大家欣赏一下Raja大神最近5月10日的投资人会议上放出的牛逼闪闪的一张幻灯片:
我就问你484牛逼闪闪,代表Intel的蓝色圆那么大,代表NVIDIA的绿色圆那么小,代表他老东家AMD的红色圆更加小。Raja大神在圆下面写了"Competitor 1"和"Competitor 2",算是给红绿两家留了点最后的面子。你要是投资人,看了这个幻灯片,是不是觉得卧槽Intel这也太牛逼了,还不赶紧投他一个亿。如果你是这么想的,那么恭喜你也被Raja大神忽悠瘸了。在Raja大神发完这张幻灯片的下一个交易日5月13日,Intel股价相比上一个交易日上涨-3.1%。个人觉得Raja大神非常需要看一下本博客的上一篇博文,学习一下什么叫做FSS。
不好意思,一黑起Raja大神我就有点刹不住车了,这段一不留神写的那么长了,最后再声明一下,对于Raja大神的这些看法都不是我瞎编的,AMD的subreddit里也不乏类似的讨论,比如【这个帖子】(International internet connection required)。
好了,废话到此结束,开始放干货~
为什么要用AMD GPU [Why AMD GPU]
和写好一篇论文一样,写好一篇教程,首先是立意要立的高高的!
使用AMD GPU做深度学习加速的优势主要有以下四点😎:
AMD提供更高的性价比,
闻到了贫穷的气息。作为长期的underdog,AMD的GPU在第三方游戏优化和能耗比上都远远落后于NVIDIA,因此只能通过提供更高的性价比来保持竞争力。相信有过挖矿经验的朋友都会发现,同等定位的A卡往往比N卡具有更强的挖矿能力,这是因为售价接近的前提下,A卡具有更高的理论计算能力,如下表所示:显卡型号 GPU芯片型号 FP32性能 售价(MSRP) 性价比 RX 480 8GB Ellesmere 5834 GFLOPS $239 24.41 GFLOPS/$ GTX 1060 6GB GP106 4375 GFLOPS $249 17.57 GFLOPS/$ 另外,现在是矿难之后,A卡二手售价白捡的一样,正是业余爱好者低成本入坑的大好机会。有人会说矿卡分分钟翻车。其实根据我多年挖矿的经验,维护良好的矿卡根本没有那么容易翻车,至少我个人挖了两年多的矿,几十块矿卡,型号包括AMD这边的RX 480、RX 470和NV这边的GTX 1060,没有一块显卡是因为挖矿挖挂了的。我对矿卡的信心主要来源于三点:1. 挖矿对显卡的稳定性要求比日常使用高多了,毕竟一块显卡跑飞了,重置驱动就要牵连这个系统上的其他所有显卡,这么重置一番损失的可都是利润,所以反而是稳定性比较高的显卡才能长期胜任挖矿任务;2. 从16年开始兴起的这一波显卡挖矿潮主要挖的是以太坊,这类挖矿算法对于核心频率并不敏感,所以挖矿的时候为了减少耗电,往往会降低核心的电压和频率,对于核心芯片的压力并不大;同时这类挖矿算法对显存延时非常敏感,而像游戏玩家那样把显存频率超的很高的话时序会变差,延时反而会增加,所以显存芯片的压力也并不是很大;3. 挖矿的显卡都是放在开放式的机架上,住在常年20度的空调房里,运行环境比闷在机箱里的游戏显卡好多了。 当然,以上的三点只针对“维护良好”的矿卡,在购买矿卡之前建议学习一些基本的测试和鉴别能力。
AMD的ROCm(Radeon Open Compute)是一个开放性非常强的项目。ROCm对标的对手是NVIDIA的CUDA(Compute Unified Device Architecture)。说起来CUDA其实是一个很有前瞻性的项目,旨在为NVIDIA的GPU提供高抽象层级的通用计算支持。最初发布于2007年,几乎每年都会迭代新版本,使得其GPU占据了全部的通用计算市场。在CUDA发布之初,GPU通用计算市场其实也就是蚊子腿那么大一块,掌管AMD显卡部门的Raja大神自然不会把它放在眼里。然而时间一晃到了2014年,深度学习正式起飞,GPU通用计算市场爆发式增长,AMD才算缓过神来,于是在2016年也推出了NVIDIA CUDA的替代品ROCm。相比于CUDA,ROCm拥有比更强的包容性和开放性,下面这张摘自AMD ROCm initiative的图片很好的诠释了ROCm的野心,从图中可以看出,ROCm和CUDA最大的区别在于其开放性:和CUDA只能在特定型号的NVIDIA GPU上运行不同,ROCm希望能在各种不同的硬件上运行。
可惜现在还不行。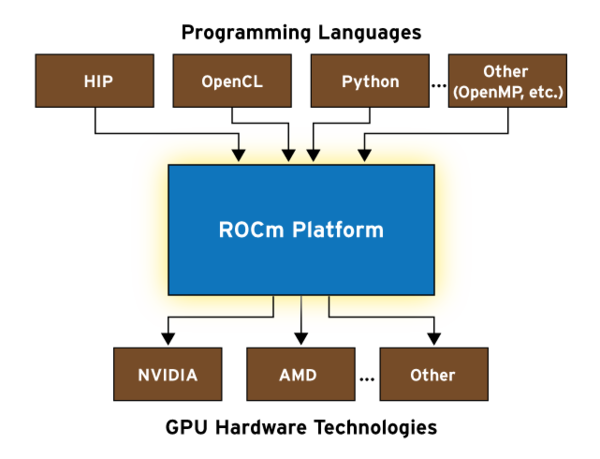
更重要的一点是,ROCm是完全开源的(【源代码】),这在贸易战背景下的今天显得格外重要。CUDA是完全闭源的软件,虽然可以免费获取,免费使用其二进制包,但是NVIDIA拥有随时修改其授权方式的权力。这可不是危言耸听,NVIDIA可是有过此类先例的:2017年的圣诞节,NVIDIA修改了其GeForce驱动程序的EULA,规定其不得在数据中心部署(链接)。在未来,NVIDIA很有可能会迫于白宫的政治压力,
Trump: Give Chaina CUDA, not good!,从而限制CUDA在中国地区的部署。相比之下,ROCm平台中的项目多采取MIT License或者其变种,通俗的来说就是最宽松的开源协议,只要求使用者给他署一个名就行。除此之外,ROCm谐音Rock'em,是不是很帅!比起遵循元辅音结构本来应该念/kju:də/但是却偏偏念成/ku:də/的CUDA强到不知道哪里去了。最后,Because we can!
Because I'm Batman!!!生命的意义在于折腾,不折腾浑身难受。
为什么要用PyTorch [Why PyTorch]
自从2017年以来,赞美PyTorch的文章已经不计其数了,所以在这里就不再赘述了。其实最主要的原因还是TensorFlow真的太难用,于是又出现了针对TensorFlow开发各种各样的Wrapper,比如有Keras,TFLearn,TensorLayer等。甚至Google自己人都觉得这个货太不好用,Google Deepmind为此也开发了自己的wrapper,叫做sonnet。TensorFlow本身就是其后端引擎的Python wrapper,然后在wrapper上面再包wrapper,这种搞法真的让我有些接受不了。
相比之下,PyTorch就简洁明了的多,动态的计算图的设计使其非常容易Debug,而且PyTorch的底层的代码更是干净的多,即使真的有自己修改底层引擎源代码的需求,改起来也会较为方便,不像TensorFlow有种“look but don't touch”的感觉。此外,AMD官方团队对于TensorFlow on ROCm的支持开发力度是所有深度学习框架中最完善的,因此如果你希望使用ROCm加速TensorFlow,仔细跟随官方文档的步骤应该就不会有太多的问题,相关的中文文档也能找到不少。而对于PyTorch的支持就比较有限,官方的文档有些过时,并且中文的相应资料几乎没有,给了我折腾的空间。
准备步骤 [Preparation]
本文假设你已经具有以下能力:
- 基本的bash shell使用。
- 安装Ubuntu操作系统。
准备步骤要完成的有:
0. 确保你的显卡支持ROCm。目前ROCm仅官方支持2015年以后新发布的GPU芯片。注意这里是按芯片的发布时间,而不是显卡发布的时间。例如2015年发布的R9 390X显卡,其GPU芯片是2013年发布的Hawaii,因此依然不能获得ROCm完整的官方支持。
目前官方支持的GPU芯片型号有:
- GFX8:
- Fiji家族,例如R9 Fury和R9 Fury X。
- Polaris家族,例如RX 480、RX 470和RX 580等。
- GFX9:
- Vega 10家族,例如RX Vega 56和RX Vega 64。
- Vega 20,例如Radeon VII。
另外,Hawaii家族的芯片可以运行ROCm平台,但是不保证功能的完全支持。Hawaii家族的显卡有R9 290,R9 390X等。
1. 安装Ubuntu操作系统。在这里推荐安装Ubuntu 16.04 LTS版本,毕竟这是官方支持的版本,出现奇怪问题的概率会小一点。不过也很推荐Ubuntu 18.04 LTS版本,作为最新的LTS版本,支持时间可以久一点,而且1804版的默认stock gnome桌面环境真的很棒,比unity高到不知道哪里去了。安装完系统之后,首先更新,安装libnuma,再重启一下:
1 | sudo apt update |
2.使用Shadowsocks加速网络连接。作为一个future proof向的攻略,本文考虑到了人类移民火星之后,火星用户访问地球互联网速度较慢的情况,地球用户可以直接跳过步骤2、3和5。本文假设你已经有了一个连接地球网速较快的shadowsocks服务器。
- 首先使系统连接Shadowsocks服务器。这里建议使用shadowsocks-qt5客户端,点击【这里】下载shadowsocks-qt5可执行文件。
- 将下载完成的文件放到你喜欢的位置,然后在这个目录打开终端,给文件添加可执行权限:
chmod a+x Shadowsocks-Qt5-3.0.1-x86_64.AppImage - 启动shadowsocks-qt5客户端:
./Shadowsocks-Qt5-3.0.1-x86_64.AppImage - 在下图所示的客户端图形配置界面里面填写正确的服务器信息,注意本地代理类型推荐使用socks5。完成后点击连接按钮。
3. 安装tsocks。使用以下命令安装tsocks:sudo apt install tsocks -y. 修改/etc/tsocks.conf文件使得最后三行设置和你shadowsocks-qt5中本地代理的设置相同,默认情况应该是这样:
1 | server = 127.0.0.1 |
4. 安装git。Ubuntu默认是没有git的,所以使用以下命令安装git:sudo apt install git -y.
5. 配置git使其通过shadowsocks加速。通过以下配置,让git走shadowsocks的socks5代理:
1 | git config --global http.proxy 'socks5://127.0.0.1:1080' |
6. WARNING:千万不要花时间去customize你的Ubuntu操作系统。这是一件很过瘾但是同时又非常花时间的事情,就像爱丽丝的兔子洞一样,你一旦钻进去了就很难钻出来了,不要问我怎么知道的,匡扶汉室都给耽误了。
安装AMD ROCm平台 [Install AMD ROCm meta-package]
由于AMD ROCm包含了单独的驱动,而且和普通的游戏驱动不能共存,所以首先确保系统中不存在AMD GPU-PRO版显卡驱动。如果有,使用以下命令删除驱动并重新启动:
1 | sudo amdgpu-pro-uninstall |
1. 添加ROCm的apt仓库。使用以下命令将ROCm的官方apt仓库添加到你的apt源中:
1 | wget -qO - http://repo.radeon.com/rocm/apt/debian/rocm.gpg.key | sudo apt-key add - echo 'deb [arch=amd64] http://repo.radeon.com/rocm/apt/debian/ xenial main' | sudo tee /etc/apt/sources.list.d/rocm.list |
2. 通过apt安装rocm-dkms包。使用以下命令安装rocm-dkms包:
1 | sudo apt update |
不出意外的话,这次安装大约要下载400MB的数据。如果你发现你的下载速度特别慢,很有可能你用的是火星网络,这时候就可以用到上面安装和配置的tsocks来加速apt。使用以下命令来代替刚才的命令:
1 | sudo tsocks apt update |
如果你的加速节点连接地球网络比较通畅,那你会发现下载时间从半天变成了十几分钟,爽到😏!
3. 为你的用户添加GPU访问权。使用以下命令将你的用户添加到可以访问GPU的用户组中:
1 | sudo usermod -a -G video $LOGNAME |
使用以下命令可以让你以后为系统新添加的用户都有GPU访问权:
1 | echo 'ADD_EXTRA_GROUPS=1' | sudo tee -a /etc/adduser.conf |
4. 将ROCm添加到PATH环境变量中。使用以下指令可以对全部用户生效:
1 | echo 'export PATH=$PATH:/opt/rocm/bin:/opt/rocm/profiler/bin:/opt/rocm/opencl/bin/x86_64' | sudo tee -a /etc/profile.d/rocm.sh |
至此,ROCm平台安装完成。重新启动以后,使用以下命令检查是否正确安装:
1 | /opt/rocm/bin/rocminfo |
如果正确安装,你的显卡设备应该显示在Agent列表中,例如我的RX 580在rocminfo中的显示结果如下:
1 | ******* |
在clinfo中显示结果如下:
1 | Number of devices: 1 |
可选。安装radeontop来监测GPU使用情况。说起来AMD的软件支持还真的是有点腿,驱动连nvidia-smi类似的功能都没有。目前只能用第三方开源软件来实现类似的功能:
1 | sudo apt install radeontop |
感觉这个radeontop也挺不好用的,显存占用也看不到。
使用Docker安装ROCm版的PyTorch [Install PyTorch on ROCm in a Docker]
0. 建议采用docker部署镜像的方式安装。首先使用以下命令安装docker:
1 | sudo apt install docker.io |
1. 拉取docker。这里官方的文档中仅提供了GFX900的镜像,而且里面的Python版本是很过分的2.7版。个人建议拉取以下镜像:
1 | docker pull rocm/pytorch:rocm2.3_ubuntu16.04_py3.6_pytorch |
这个镜像中Python版本是还行但任然不是最新的3.6版。
拉取镜像大约要下载4GB的数据,不过由于Docker Hub在火星也有CDN,因此大部分用户应该都能获得还过得去的下载速度。
2. 启动docker。使用以下命令启动并进入Docker:
1 | sudo docker run -it -v $HOME:/data --privileged --rm --device=/dev/kfd --device=/dev/dri --group-add video rocm/pytorch:rocm2.3_ubuntu16.04_py3.6_pytorch |
其中-v $HOME:/data命令使得你的home目录被映射到docker中的/data目录。
3. 运行PyTorch测试。 在Docker中使用以下命令运行PyTorch自带的测试:
1 | cd /pytorch |
大部分测试应该都能通过。由于ROCm的PyTorch并没有完全在每种GPU上支持PyTorch的全部CUDA函数,小部分很有可能通过不了。
性能测试 [Performance test]
至此终于算是大功告成,成功安装了PyTorch on ROCm。我还在自己的设备上运行了简单的视觉类测试。
CIFAR数据集上的性能。我这里有一份自己写的CIFAR数据集上训练VGG-16网络的代码,可以通过以下命令获取:
1 | git clone https://github.com/JC-S/TensorClog_Public |
注意在运行之前,首先将utils.py文件中的torch.backends.cudnn.benchmark = True注释掉。这个flag用于提高Pascal及更新的NVIDIA GPU的性能,在ROCm环境下可能会导致死循环。注释完成之后,使用python pretrain.py命令训练VGG-16网络。
在我的测试中,RX 580 4GB,核心频率1380 MHz,显存频率1750 MHz,运行一个epoch训练大约耗时33秒。作为比较,GTX 1080 Ti运行一个epoch大概为16秒。目测RX 580的PyTorch训练性能和GTX 1070或者GTX 1070 Ti持平,按3D渲染性能来比较的话妥妥的算是越级打怪了。
最后
AMD的CPU在最近三年内给我们上演了underdog takeover的大戏,作为一个吃瓜群众我看的还是挺过瘾的。希望这篇博文能帮到使用AMD GPU又对Deep learning感兴趣的朋友。顺便,还希望Raja大神不要辜负我的期望,在Intel能继续稳定发挥,这样我若干年以后也可以拿这篇博文来对某不信邪的光头说一句‘Told you’😎。